有限预算, 打造个人私有 AI 主机
2025年2月27日 · 278 字 · 2 分钟
本文作者, 介绍了他花费大概 1700 欧元, 搭建的一台拥有 48GB 显存的工作站的经历.
原文: https://ewintr.nl/posts/2025/building-a-personal-private-ai-computer-on-a-budget/
Claude 翻译, 人工校对, 略有删改.
众所周知,世界仍在疯狂地尝试开发更多、更新、更好的AI工具。
主要方式是向这个问题投入海量资金。这些数十亿资金中的大部分都用于构建廉价或免费的服务,这些服务往往以巨大亏损运营。
运营这些服务的科技巨头都希望吸引尽可能多的用户,以便他们能够占领市场,成为能够提供这些服务的主导或唯一方。这是典型的硅谷剧本。一旦达到主导地位,可以预期的"劣化"(enshittification,指产品质量逐渐下降的过程)就会开始。
但还是有希望的。新玩家撼动市场的技巧之一是通过免费发布他们的模型,并采用宽松的许可,从而削弱现有竞争对手。这正是DeepSeek刚刚对他们的DeepSeek-R1所做的事情。谷歌早先也通过Gemma模型做了类似的事,Meta也通过Llama这么做了。我们可以自己下载这些模型并在自己的硬件上运行它们。更好的是,人们可以获取这些模型并清除其中的偏见。我们可以下载这些经过清洗的模型并在自己的硬件上运行它们。然后我们终于可以拥有一些真正有用的大语言模型。
不过,硬件可能是个障碍。如果你想在本地运行一个大语言模型,有两个选择:你可以获得一个来自Nvidia的大型、强力的显卡,或者你可以购买一台Apple设备。无论哪种都很昂贵。大语言模型性能如何, 主要取决于可用内存的数量。对于GPU来说是VRAM(显存),对于Apple设备来说则是普通RAM(内存)。这个数字越大越好。更多的RAM意味着可以运行更大的模型,这将大大提高输出质量。就我个人而言,我认为至少需要超过24GB才能运行任何有用的东西。这将容纳一个320亿参数的模型,并有一点余量。构建或购买一个配备这些设备的工作站很容易花费数千欧元。
那么,如果你没有那么多钱可以花费,该怎么办呢?你可以购买二手设备!这是一个可行的选择,但一如既往,天下没有免费的午餐。内存可能是主要考虑因素,但不要低估内存带宽和其他规格的重要性。较旧的设备在这些方面的性能会较低。但现在不要太担心这些。我对构建至少能以可用方式运行大语言模型的东西感兴趣。当然,最新的Nvidia卡可能会更快,但关键是能够做到这一点。强大的在线模型可能很好,但至少应该有选择切换到本地模型的选项,如果情况需要的话。
以下是我尝试在不花太多钱的情况下构建这样一个能力强大的AI电脑。我最终得到了一个拥有48GB显存的工作站,花费了大约1700欧元。我本可以花更少的钱。例如,严格来说,购买全新的伪GPU(见下文)并非必要,或者我可以找人为我3D打印散热风扇罩,而不是从遥远的国家运送现成的。我承认,当我发现我必须购买另一个零件才能使这一切工作时,我在最后变得有点不耐烦。对我来说,这是一个可以接受的权衡。
硬件
这是完整的成本明细:
| 部件 | 价格 | 说明 |
|---|---|---|
| 2 x Nvidia Tesla P40 | € 659,98 | GPU |
| HP Z440 工作站 | € 568,50 | 我已经拥有这个 |
| NZXT C850 Gold | € 135,17 | 电源 |
| Gainward GT 1030 | € 108,75 | 伪GPU |
| Nvidia Tesla 散热风扇套件 | € 98,51 | 包括运费 |
| MODDIY 主电源适配器线 | € 39,99 | HP真难用 |
| Akasa 多风扇适配器 | € 5,05 | 用于GPU风扇 |
| 总计 | € 1695.15 |
以下是安装所有部件后首次启动时的样子:

首次启动
我将在下面提供关于部件的一些背景,之后,我将运行一些快速测试来获得一些性能数据。
HP Z440 工作站
选择Z440很容易,因为我已经拥有它。这是起点。大约两年前,我想要一台可以作为虚拟机主机的电脑。Z440有一个12核的Xeon处理器,这台配备了128GB的RAM。多线程和大量内存,这应该适合托管虚拟机。我从二手市场购买的,然后将512GB硬盘换成了6TB硬盘,用于存储这些虚拟机。运行大语言模型不需要6TB,因此我没有将其包含在成本明细中。但如果你想要部署多个模型,512GB可能不够。
我开始喜欢上这台工作站。它非常耐造,我没有遇到任何问题。至少,直到我开始这个项目。事实证明,HP不喜欢竞争,当更换组件时,我遇到了一些困难。
2 x NVIDIA Tesla P40
这是神奇的成分。GPU很贵。但是,与HP Z440一样,通常可以找到曾经是顶级且仍然非常强大的旧设备,二手的,价格相对较低。这些Tesla原本是为服务器群运行设计的,用于3D渲染和其他图形处理。它们配备了24GB的VRAM。不错。它们适合PCI-Express 3.0 x16插槽。Z440有两个这样的插槽,所以我们买两个。现在我们有48GB的VRAM。不错, 达到我们最低内存要求的2倍。
问题在于它们是为服务器设计的。它们在普通工作站的PCIe插槽中可以正常工作,但在服务器中,散热管理方式不同。强大的GPU消耗大量电力,可能会变得非常热。这就是为什么消费级GPU总是配备大型风扇的原因。卡需要自行处理散热。然而,Tesla完全没有风扇。它们同样会变热,但期望服务器提供稳定的气流来冷却它们。卡的外壳有点像管道,你有两个选择:从一侧吹入空气或从另一侧吹入。这就是所谓的灵活性如何?但你必须向其中吹入一些空气,否则一旦你开始使用它,就会损坏它。
解决方案很简单:只需在管道的一端安装一个风扇。实际上,似乎已经形成了一整个小产业,有人销售3D打印的风扇罩,正好将标准60mm风扇固定在适当的位置。问题是,卡本身已经相当笨重,很难找到能容纳两张卡和两个风扇支架的配置放入机箱中。卖给我两张Tesla的卖家很好心地包含了两个带有风扇罩的风扇,但我无法将所有这些都装入机箱中。那我们该怎么办?我们购买更多部件。
NZXT C850 Gold
这就是事情变得烦人的地方。HP Z440有一个700瓦的PSU,这可能足够了。但我不确定,而且我无论如何都需要购买一个新的PSU,因为它没有连接Tesla的正确接口。使用这个方便的网站,我推断出850瓦应该足够,于是我购买了NZXT C850。这是一个模块化PSU,意味着你只需插入你实际需要的线缆。它附带了一个整洁的袋子来存放备用线缆。有一天,我可能会好好清洁它并将其用作洗漱袋。
不幸的是,HP不喜欢非HP的东西,所以他们使更换PSU变得困难。它在物理上不匹配,他们还更改了主板和CPU连接器。我一生中见过的所有PSU都是矩形盒子。HP PSU也是一个矩形盒子,但有一个切口,确保没有普通的PSU能匹配。这完全没有技术原因。这只是为了捣乱。
安装最终通过使用网格上的两个随机孔解决,我设法将这些孔与NZXT上的螺丝孔对齐。它现在稳定地挂着,我很幸运这一切能够工作。我看过YouTube视频,人们不得不使用双面胶带。
连接器需要…另一次购买。

不酷,HP。
Gainward GT 1030
在这个消费级工作站中使用服务器GPU还有另一个问题。Tesla旨在进行数值计算,而不是玩视频游戏。因此,它们没有任何用于连接显示器的端口。HP Z440的BIOS不喜欢这一点。如果没有输出视频信号的方式,它拒绝启动。这台电脑将无头运行,但我们别无选择。我们必须获得第三个显卡,我们不打算使用它,只是为了让BIOS满意。
当然,这可以是你能找到的最简陋的卡,但有一个要求:我们必须使其适合主板。Tesla很笨重,填满了两个PCIe 3.0 x16插槽。剩下的能物理上容纳卡的插槽只有一个PCIe x4插槽和一个PCIe x8插槽。查看这个网站了解这些名称的含义。然而,不能购买任何x8卡,因为通常即使GPU被宣传为x8,其上的实际连接器可能与x16一样宽。电子上它是x8,物理上它是x16。这在这个主板上行不通,我们确实需要小连接器。
Nvidia Tesla 散热风扇套件
如前所述,挑战在于找到适合机箱的风扇罩。经过一些搜索,我在Ebay上找到了这个套件并买了两个。它们随带一个40mm风扇,一切完美匹配。
请注意,它们会产生很多噪音。我想, 你应该不会想把这些带风扇的电脑放在桌子下面。
为了监控温度,我快速编写了这个脚本并将其放入cron作业中。它定期读取GPU上的温度并将其发送到我的Homeassistant服务器:
#!/bin/bash
# 配置
HA_URL="http://localhost:8123"
TOKEN="<your_long_lived_access_token>"
# 向HA传感器发送数据的函数
send_to_ha() {
local gpu_id=$1
local temp=$2
# 为REST API调用定义有效载荷
PAYLOAD='{"state": "'"$temp"'"}'
# 发送POST请求更新HA中传感器实体的状态
curl -X POST \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
"$HA_URL/api/states/sensor.gpu_${gpu_id}_temp" \
--data "$PAYLOAD"
}
# 使用nvidia-smi获取GPU温度并将它们发送到HA
nvidia-smi -q | grep 'GPU Current Temp' | awk '{print $5}' | while read -r temp; do
# 假设GPU从0开始索引
gpu_id=$(($gpu_id + 1))
if [ "$temp" ]; then
send_to_ha $(($gpu_id - 1)) "$temp"
fi
done
# 重置GPU索引计数器(可选)
unset gpu_id
在Homeassistant中,我向仪表板添加了一个图表,显示随时间的值:
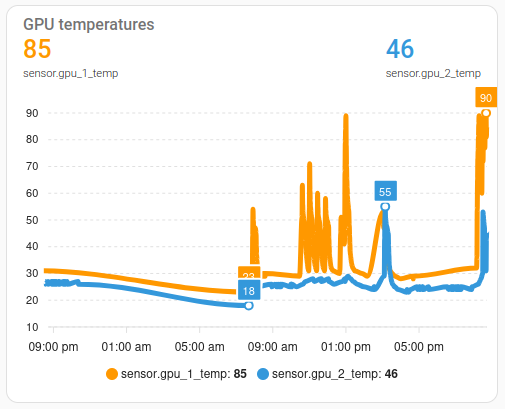
GPU温度
如图所示,风扇很吵,但效果不是特别好。90度太热了。我在互联网上搜索了合理的上限,但找不到任何具体信息。Nvidia网站上的文档提到了47摄氏度的温度。但是,他们指的是GPU周围环境空气的温度,而不是芯片上的测量值。你知道,实际报告的数字。谢谢,Nvidia。这很有帮助。
经过进一步的搜索和阅读我的互联网同胞的意见,我猜只要保持在70度以下就没问题。但不要把这当作定论。
我的第一次尝试是通过设置GPU的最大功耗来解决这个问题。根据这个Reddit帖子,可以降低卡的功耗45%,只损失15%的性能。我试了一下…完全没有注意到任何区别。当时只有几分钟的经验,我不确定性能下降情况,但温度特性肯定没有变化。
然后我突然想到一个点子。你看,就在GPU风扇之前,HP Z440机箱中有一个风扇。在上面的照片中,它位于右角,黑盒子内。这是一个将空气吸入机箱的风扇,我认为这将与向Tesla吹入空气的GPU风扇协同工作。但这个机箱风扇根本没有转动,因为计算机的其余部分不需要任何散热。查看BIOS,我找到了设置机箱风扇最小空转速度的选项。它的范围从0到6颗星,当前设置为0。将其设置为更高值对温度产生了奇迹般的效果。它也产生了更多噪音。
我不情愿地承认,在调整BIOS设置时,第三个显卡很有帮助。
MODDIY主电源适配器线和Akasa多风扇适配器
幸运的是,有时候事情就是这么简单。这两个项目即插即用。MODDIY适配器线将PSU连接到主板和CPU电源插座。
我使用Akasa从4针Molex为GPU风扇供电。它有一个很好的功能,可以为两个风扇提供12V电源,为另外两个提供5V电源。后者显然降低了风扇的速度,从而降低了散热能力。但它也减少了噪音。通过调整这个和机箱风扇设置,我找到了噪音和温度之间可接受的权衡。至少现在是这样。也许夏天我需要重新考虑这个问题。
一些数据
推理速度
我通过使用–verbose标志运行ollama,并要求它五次编写一个故事,然后取平均值来收集这些数据:
$ ollama run gemma2:27b --verbose
>>> 你能给我写一个关于乌龟和兔子的故事吗,但是
其中涉及到一场比赛,看谁能每秒获得最多的token?
性能方面,ollama配置为:
OLLAMA_FLASH_ATTENTION=1
OLLAMA_KV_CACHE_TYPE=q8_0
所有模型都使用ollama默认的量化,如果你不指定任何东西,它会为你拉取这些模型。
| 模型 | 最大功率 | 每秒token数 |
|---|---|---|
| mistral-small:24b | 250W | 15.23 |
| mistral-small:24b | 140W | 13.95 |
| gemma2:27b | 250W | 13.90 |
| gemma2:27b | 140W | 13.50 |
| qwen2.5-coder:32b | 250W | 10.75 |
| qwen2.5-coder:32b | 140W | 10.60 |
| llama3.3:70b | 250W | 5.35 |
| llama3.3:70b | 140W | 5.00 |
| deepseek-r1:70b | 250W | 5.30 |
| deepseek-r1:70b | 140W | 4.94 |
另一个重要发现:Terry是乌龟最受欢迎的名字,其次是Turbo和Toby。Harry是兔子的最爱。所有大语言模型都喜欢头韵。
功耗
几天来,我一直关注工作站的功耗:
| 状态 | 功率 |
|---|---|
| 空闲 | 80W |
| 32b模型加载 | 123W |
| 32b模型工作 | 241W |
| 70b模型加载 | 166W |
| 70b模型工作 | 293W |
请注意,这些数据是在140W功率上限激活的情况下获取的。
如你所见,还有另一个权衡需要做。将模型保持在显卡上可以改善延迟,但消耗更多电力。我目前的设置是加载两个模型,一个用于编码,另一个用于通用文本处理,并在最后使用后最多保持一小时在GPU上。
结论
在所有这些之后,我对启动这个项目感到高兴吗?是的,我想是的。
我花费的钱比计划的多一点,但我得到了我想要的:一种在本地运行中型模型的方式,完全在我自己的控制之下。
从我已经拥有的工作站开始,看看我能走多远,这是一个很好的选择。如果我从头开始一台新机器,肯定会花费更多。也会花费更长时间,因为会有更多选择。我也会非常倾向于跟随炒作,购买最新最好的一切。新的闪亮玩具很有趣。但如果我买新东西,我希望它能使用多年。现在要自信地预测5年后AI的发展方向是不可能的,所以拥有一台更便宜的机器,至少能用一段时间,对我来说感觉很满意。
祝你在自己的AI旅程中好运。如果我发现新的或有趣的东西,我会再报告。
作者:极目楚天舒
链接:https://talkaboutos.com/posts/building-a-personal-private-ai-computer-on-a-budget/
声明:除非另有声明,本文采用 CC BY-NC-SA 3.0 协议,转载请注明。
赞助:若你觉得本文对你有启发,非常欢迎你成为我的 Sponsor ,感恩遇见